
Aprendiendo a cambiar

Por Alejandro Cervantes.
¿Qué pensaríamos del aprendizaje automático (ML) si todo modelo desarrollado tuviese fecha de caducidad? ¿Puede un ingeniero afirmar que su modelo, entrenado un tiempo significativo en potentes entornos de computación en la nube, tendrá el mismo comportamiento hoy que en un año?¿o en un día?¿Y si perdiese validez cada minuto?
El mecanismo más utilizado en ML se denomina “aprendizaje offline” y tiene como suposición fundamental que nuestros modelos pueden entrenarse previamente con una colección de datos del pasado, para luego para hacer predicciones o extraer conclusiones que serán válidas por un tiempo indefinido, cuando el sistema se “ponga en línea”. Se trata de una suposición de régimen estacionario.
Ahora bien, el sentido común ya nos anima a sospechar de una validez indefinida; esto no corresponde verdaderamente con nuestra experiencia, especialmente (pero no solo) en lo que se refiere a sistemas sociales. En general, los seres humanos nos hemos acostumbrado a etiquetar nuestro conocimiento como provisional; es un continuo devenir (“panta rei”), como el que se atribuye a Heráclito.
Algunos fenómenos en los que el cambio aparece son los que tienen un componente social o los que incluyen elementos en competencia evolutiva: la evolución en significado o uso de los términos en el lenguaje, los cambios regulatorios, los cambios en los gustos y tendencias del consumidor, las adaptaciones de virus y bacterias para luchar contra nuestros medicamentos o variar sus formas de expansión, y muchos otros.
Este problema se ha denominado de formas diferentes a medida que se ha tratado desde diversas perspectivas, como es “cambio de concepto” o “cambio de régimen” [1]. En un contexto amplio, se aborda el caso general de que el modelado del sistema en un tiempo deje ser válido en un tiempo posterior. Puede que el sistema en sí mismo haya cambiado; o puede ocurrir que el modelo no tenga en cuenta un contexto oculto que haya variado con el tiempo. Existen estudios que realizan una taxonomía de los diversos tipos de cambio [2]. Una revisión muy reciente sobre el campo se centra no sólo en los momentos de régimen no estacionario en general, sino en el tratamiento y aprovechamiento de “lo ya aprendido” para adaptarse al llamado cambio recurrente [3] (Figura 1).
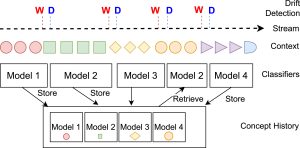
Figura 1: Entrenamiento continuo de modelos y almacenaje/recuperación, monitorizado mediante detectores de cambio (Figura reproducida de [3])
Hay una gran diversidad de soluciones: sistemas adaptativos que usan algoritmos de aprendizaje que crean modelos “plásticos”, que se pueden actualizar de forma continua: por ejemplo, árboles de decisión como HAT [6] que son capaces de ir alterando su estructura a medida que sus predicciones se muestran desajustadas. En otros casos, la adaptación parte de métodos clásicos (árboles, redes, etc.), que se degradan con el cambio. A partir de estos se crea un modelo adaptable mediante el uso de técnicas de ensamble [7,8]. Como una sociedad humana, un ensamble estará compuesto por “instrumentos” concordantes y disonantes, sin descartar estos últimos aunque su peso sea reducido en la decisión colectiva del ensamble. Monitorizando el flujo de datos y el resultado del ensamble, un método adaptativo decidirá qué aprender, qué recuperar, y qué olvidar. Y existe la posibilidad de que el cambio llegue, y súbitamente aquella voz discordante, pero ya preparada, puede ser la que nos de la mejor explicación sobre los datos que observamos: “y sin embargo, se mueve”.
Referencias
[1] Tsymbal, A. (2004). The Problem of Concept Drift: Definitions and Related Work: Technical report: TCD-CS-2004-15, Department of Computer Science Trinity College, Dublin.
[2] Webb, G. I., Hyde, R., Cao, H., Nguyen, H. L., & Petitjean, F. (2016). Characterizing concept drift. Data Mining and Knowledge Discovery, 30(4), 964–994.
[2] Elwell, R., & Polikar, R. (2011). Incremental learning of concept drift in nonstationary environments. IEEE Transactions on Neural Networks, 22(10), 1517–1531.
[3] Andrés L. Suárez-Cetrulo, David Quintana, Alejandro Cervantes, A survey on machine learning for recurring concept drifting data streams, Expert Systems with Applications, Volume 213, Part A, 2023, 118934, ISSN 0957-4174, https://doi.org/10.1016/j.eswa.2022.118934.
[4] Wares, S., Isaacs, J., & Elyan, E. (2019). Data stream mining: Methods and challenges for handling concept drift. SN Appl Sci, 1(11), 1–19.
[5] Bahri, M., Bifet, A., Gama, J., Gomes, H. M., & Maniu, S. (2021). Data stream analysis: Foundations, major tasks and tools. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 11(3), Article e1405.
[6] Bifet, A., Gavaldà, R. (2009). Adaptive Learning from Evolving Data Streams . In: Adams, N.M., Robardet, C., Siebes, A., Boulicaut, JF. (eds) Advances in Intelligent Data Analysis VIII. IDA 2009. Lecture Notes in Computer Science, vol 5772. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-03915-7_22
[7] Montiel, J., Mitchell, R., Frank, E., Pfahringer, B., Abdessalem, T., & Bifet, A. (2020). Adaptive XGBoost for evolving data streams. In 2020 international joint conference on neural networks (pp. 1–8). IEEE.
[8] Gomes, H. M., Bifet, A., Read, J., Barddal, J. P., Enembreck, F., Pfharinger, B., et al. (2017). Adaptive random forests for evolving data stream classification. Machine Learning, 1–27.