
Aprendizaje Federado, Computación Segura Multi-Parte y protección de la privacidad en proyectos de investigación
La comunidad científica trabaja activamente en para neutralizar las amenazas planteadas por las metodologías de trabajo basadas en IA. Existen dos enfoques que merece la pena comentar en profundidad: el Aprendizaje Federado y la Computación Segura Multi-Parte.
El Aprendizaje Federado (Federated Learnig o FL) es una estrategia descentralizada para el entrenamiento de modelos de aprendizaje automático, enfatizando la importancia de los criterios de compliance, protección de datos y prevención de ciberdelincuencia. Para entender por qué, comparemos estos dos enfoques:
- Enfoque concentrado: todos los datasets para el entrenamiento de modelos están en un mismo entorno. Si se vulnera la seguridad de este entorno, todos los datos quedarían expuestos.
- Enfoque distribuido (FL): los datos no salen de su fuente original y los propietarios retienen por tanto el control sobre los mismos. Si se vulnera la seguridad de un dispositivo, solo estarán expuestos los datos de ese dispositivo.
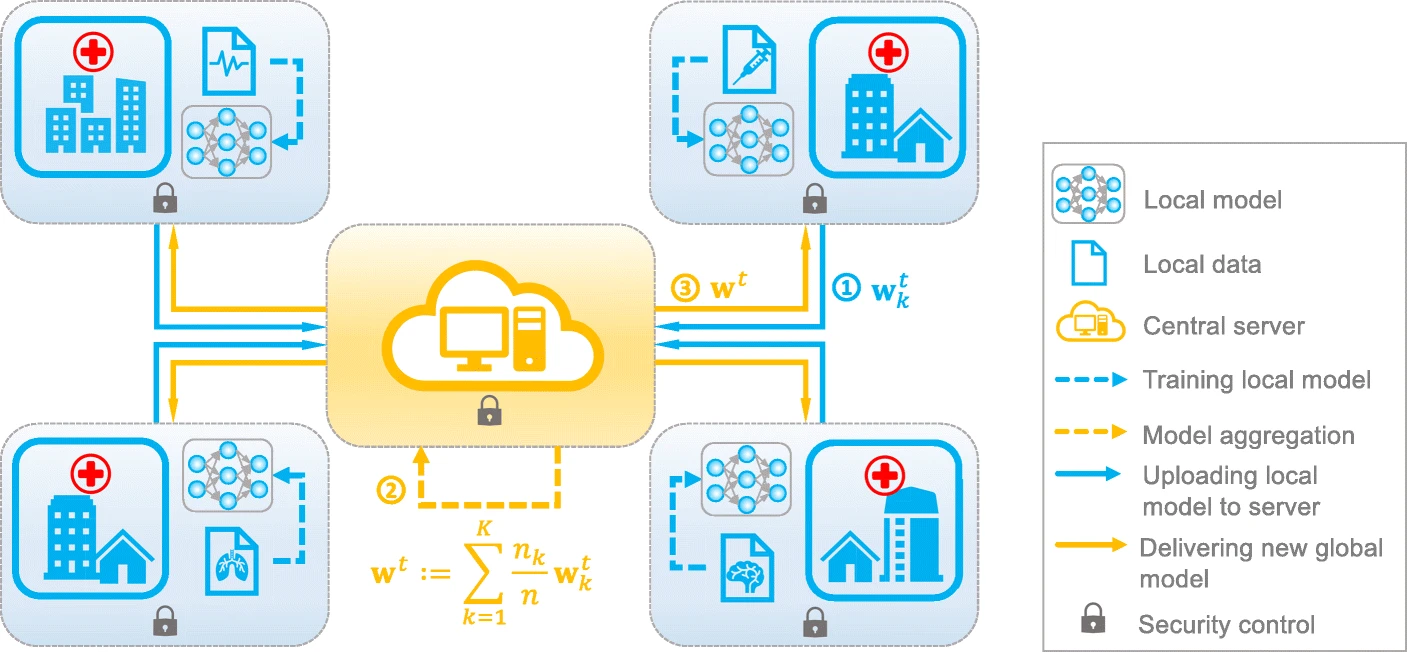
Así, el FL permite que los modelos se entrenen localmente en dispositivos, como teléfonos inteligentes, sensores IoT o servidores de empresas. Estos modelos locales luego envían actualizaciones de los pesos del modelo al servidor central, donde se realiza la agregación para mejorar el modelo global. Este proceso se repite iterativamente, mejorando la precisión sin comprometer la privacidad de los datos individuales.
Existen además otras ventajas interesantes:
- En entornos donde varias partes desean colaborar en la construcción de un modelo, el FL permite esta colaboración sin que cada parte tenga que revelar sus datos completos.
- Al estar los datos distribuidos, los riesgos asociados a la ciberseguridad se diluyen, y cada propietario puede aplicar sus políticas.
Sin embargo, un enfoque basado en FL tiene también su talón de Aquiles:
¿Cómo relacionar la información de los distintos sets entre sí sin incurrir en duplicidades y sin compartir datos que pudieran permitir identificar entidades (riesgo para la privacidad o para el secreto industrial)?
Aquí es donde entra en juego la Computación Segura Multi-Parte (SMPC), la cual permite a varias entidades colaborar en el procesamiento de datos sin revelar información sensible a las demás partes. Este procedimiento garantiza la seguridad y privacidad de los datos incluso cuando se comparten y procesan de manera conjunta.
Existen varios protocolos SMPC, pero su funcionamiento, esencialmente, podemos resumirlo así:
- Cada parte segmenta sus datos aleatoriamente generando N valores.
- Se comparten claves criptográficas entre las partes para permitir la operación segura durante el proceso.
- Las partes ejecutan el protocolo SMPC acordado, realizando el procesamiento de los datos compartidos sin conocer la información completa.
- Al finalizar el protocolo SMPC, las partes colaboran en la agregación segura de los resultados.
Lecturas recomendadas
Rieke, N., Hancox, J., Li, W. et al. The future of digital health with federated learning. npj Digit. Med. 3, 119 (2020). https://doi.org/10.1038/s41746-020-00323-1
Li Li, Yuxi Fan, Mike Tse, Kuo-Yi Lin, A review of applications in federated learning, Computers & Industrial Engineering, Volume 149, 2020, 106854, ISSN 0360-8352, https://doi.org/10.1016/j.cie.2020.106854
Xu, J., Glicksberg, B.S., Su, C. et al. Federated Learning for Healthcare Informatics. J Healthc Inform Res 5, 1–19 (2021). https://doi.org/10.1007/s41666-020-00082-4